Crawl
Data Miner Crawl is for when you have a list of items on a webpage that you need to click into to see additional data. This is a two step process that uses a combination of a List Recipe and a Detail Recipe .
Crawl Process Overview
1) This process requires two recipes. The first recipe is used on the search results page or list page and extracts the detail page URLs from every individual row.
2) You will save the list of URLs and then using a Crawl, Data Miner will then visit every URL and apply the second recipe, which is used to scrape the details.
3) Once the process is complete, you will have a file with the combined data from the list page and each detail page. Continue below to see complete documentation.
Crawl Tutorial Video
Step By Step Instructions:
Part One - Collecting the URLs
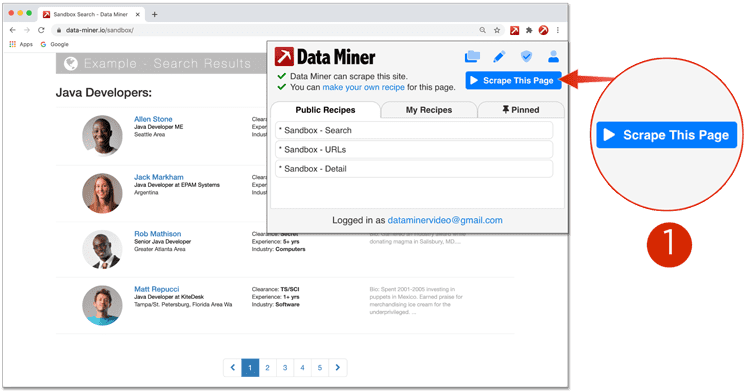
- Navigate to the search results page you want to scrape, launch Data Miner and click scrape this page.
- Click Page Scrape from the left side menu.
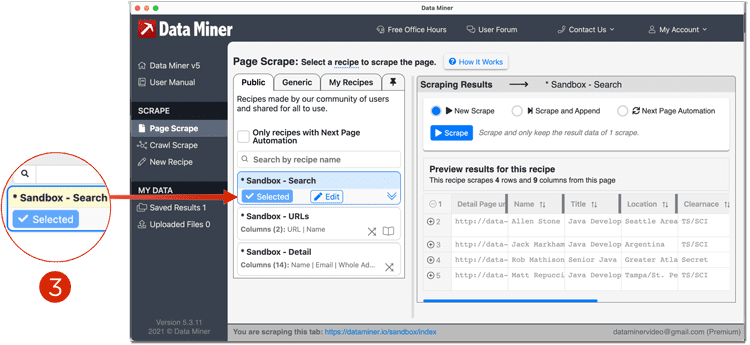
- Now preview a recipe that captures the URLs of each search results row. You can choose from Public, Generic or My Recipes. If no Public Recipes are available you will have to make your own. You can learn how to do that here: Recipe Creator
-
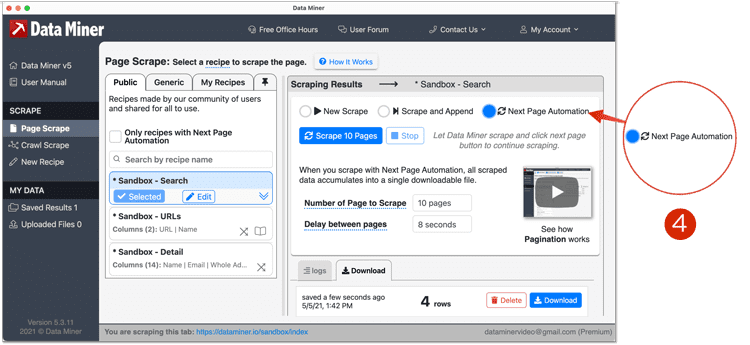
Once you see a preview of URLs on the right had side, you must choose your scrape method. In most cases, the list
page will have multiple pages with a Next button. So we will use that as our example. Choose Next Page Automation.
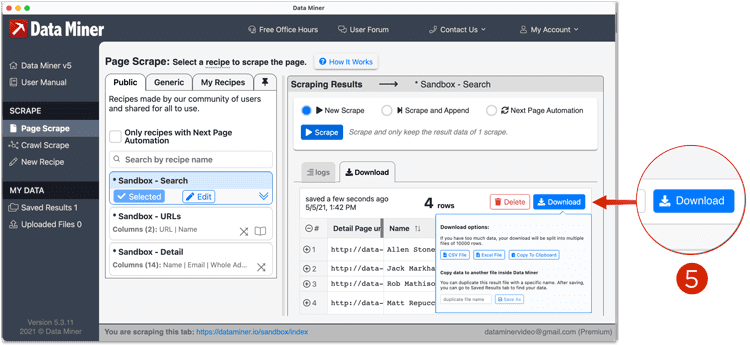
You can learn more about Next Page Automation from our Page Scrape Tutorial - Once you've acquired all the URLs. You can continue to the Download section. From here you can Save the URLs or download them. For this example, we will be using the Save option. If you download, you must later upload the URLs as a CSV.
- Give the file a unique Name and click "Save As".
Part Two - Running a Crawl
- Once you have a list of URLs, Click Crawl Scrape from the left side menu.
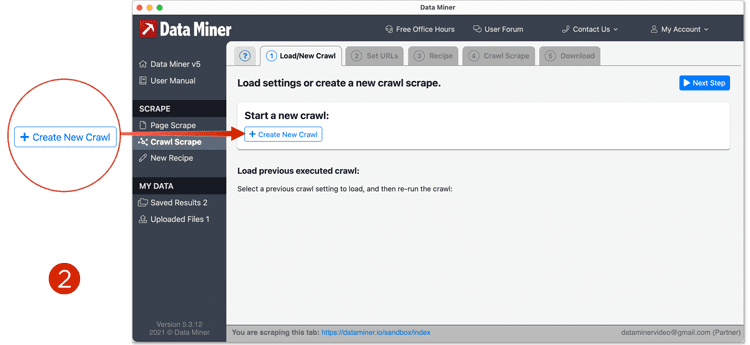
- Click "Load/New Crawl" from the top tabs in Data Miner. And then from the center options, click "Create new Crawl".
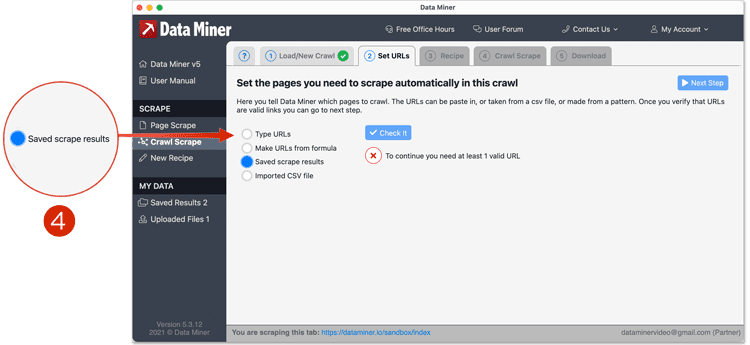
- Next we will tell Data Miner where the URLs will be coming from. This is done from the "Set URLs" Tab. There are multiple options which are covered in the advanced Crawl tutorials (coming soon) . For this example, we will be using "Saved Scrape Results"
- Click "Saved Scrape Results"
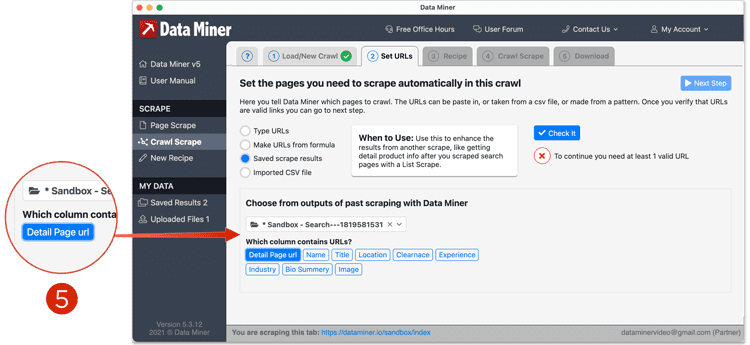
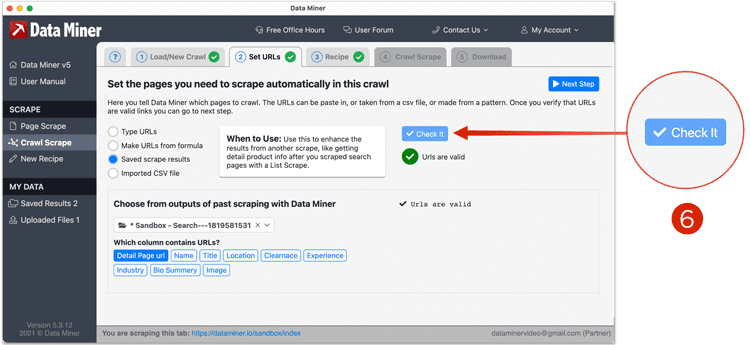
- Now from the drop down menu, choose the file that was saved from Step One and click the column header that contains the URL.
- Click "Check it", this will check that the URLs are valid. If some return invalid, these will be skipped
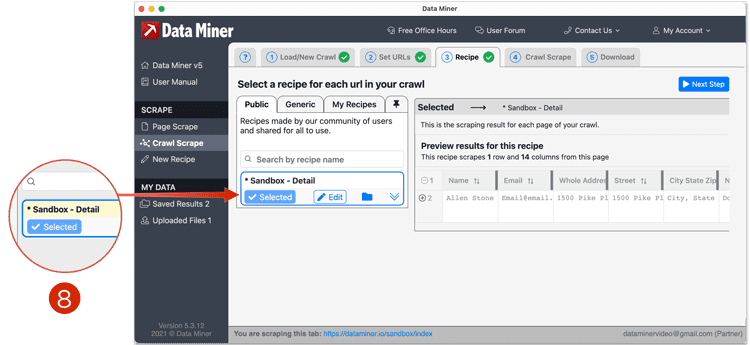
- Once the URLs are confirmed, move onto the Recipe tab. This is where you will select the detail recipe that will be used on each URL to scrape the data. If you do not have a detail recipe, you can make one by following our tutorials on how to create recipes.
- Once the recipe is selected, you will see a preview scrape to the right.
- If the data looks good, continue to the Crawl Scrape tab
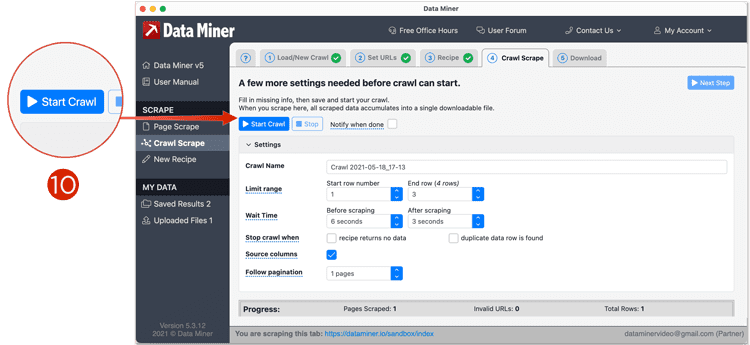
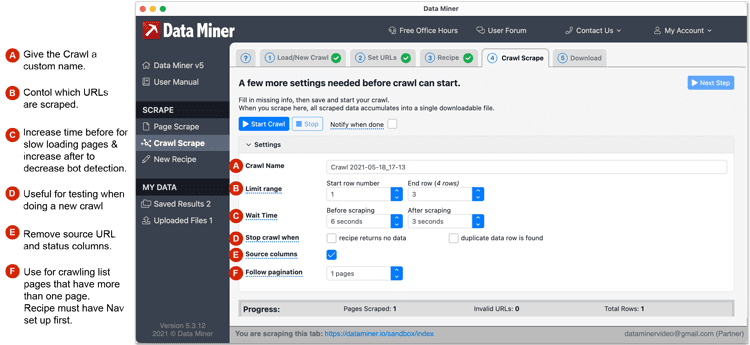
- From the Crawl tab, you will fill out the Crawl Settings and then click Start Crawl. A breakdown of the settings can be found at the bottom of the page
- Data Miner will now visit each URL one by one, applying the detail recipe and scraping the data. The scraped data will begin to accumulate in the Download tab after a few seconds.
-
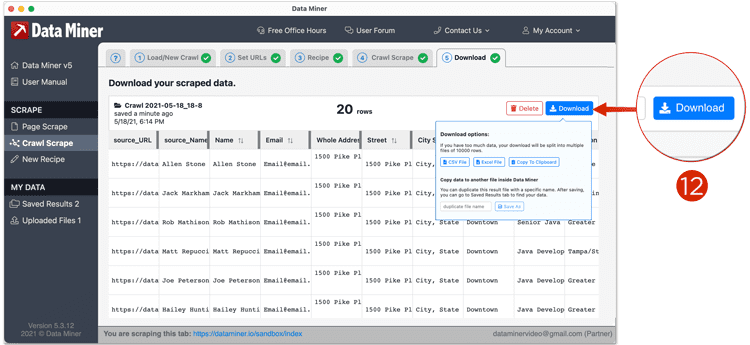
From the Download tab you will be able to save the data, or download it as a CSV, Excel file, or copy it to your
clipboard.
![crawl download]()
Crawl Settings
Try on your own!
Using our Practice Sandbox try running through the above steps on your own!
To continue your learn please visit our additional tutorials
Do you not see any Public or Generic Recipes? You can learn to make recipes yourself from our How to Write Recipes section.